LLM提示工程入門指南
LLM提示工程入門指南
概述與背景
隨著ChatGPT、Claude等大語言模型(LLM)的普及,如何與AI進行有效溝通成為一項關鍵技能。提示工程(Prompt Engineering)就是研究和優化與LLM交互方式的學問,它能幫助我們從AI獲得更準確、更有用的回應。
無論你是開發者、內容創作者還是普通用戶,掌握提示工程都能讓你的工作效率大幅提升。本指南將帶你從零開始,系統性地學習提示工程的核心概念和實用技巧。
本文你能學到
- ✅ 5種核心提示策略的對比與選擇
- ✅ 3個完整的實戰案例(代碼生成、數據分析、內容創作)
- ✅ 進階技巧:思維鏈、ReAct、思維樹
- ✅ 10個常見問題與解決方案
- ✅ 提示模板庫,可直接複用
核心概念
什麼是提示(Prompt)?
提示是我們輸入給LLM的文本內容,它可以是問題、指令、描述或任何形式的輸入。提示的質量直接決定了AI回應的質量。
提示的構成 = 指令 + 上下文 + 輸入數據 + 輸出格式graph TB
subgraph 提示構成
A[指令<br/>Instruction] --> E[完整提示]
B[上下文<br/>Context] --> E
C[輸入數據<br/>Input Data] --> E
D[輸出格式<br/>Output Format] --> E
end
E --> F[LLM處理]
F --> G[AI回應]
style A fill:#e1f5fe
style B fill:#e8f5e9
style C fill:#fff3e0
style D fill:#f3e5f5
style E fill:#fce4ec
style F fill:#fff9c4
style G fill:#c8e6c9提示工程的基本原則
- 清晰性:提示應該明確、具體,避免歧義
- 完整性:提供足夠的背景信息和上下文
- 結構化:使用適當的格式組織提示內容
- 可迭代:願意根據結果調整和優化提示
五種核心提示策略對比
graph LR
subgraph 提示策略選擇決策樹
A[任務類型?] --> B{複雜度}
B -->|簡單| C[零樣本<br/>Zero-shot]
B -->|中等| D{需要示例?}
B -->|複雜| E{需要推理?}
D -->|是| F[少樣本<br/>Few-shot]
D -->|否| C
E -->|是| G{需要工具?}
E -->|否| H{多路徑決策?}
G -->|是| I[ReAct]
G -->|否| J[思維鏈<br/>CoT]
H -->|是| K[思維樹<br/>ToT]
H -->|否| J
end
style A fill:#fff9c4
style B fill:#e1f5fe
style C fill:#c8e6c9
style F fill:#c8e6c9
style I fill:#c8e6c9
style J fill:#c8e6c9
style K fill:#c8e6c9sequenceDiagram
participant U as 用戶
participant L as LLM
participant T as 工具(ReAct)
Note over U,T: 零樣本流程
U->>L: 直接提問
L-->>U: 直接回答
Note over U,T: 思維鏈流程
U->>L: 複雜問題+逐步思考請求
L->>L: 步驟1推理
L->>L: 步驟2推理
L->>L: 步驟N推理
L-->>U: 完整推理結果
Note over U,T: ReAct流程
U->>L: 需要外部信息的問題
L->>L: 思考:需要什麼信息
L->>T: 調用工具
T-->>L: 返回結果
L->>L: 行動:基於結果分析
L-->>U: 最終答案| 策略 | 適用場景 | 優點 | 缺點 | 推薦指數 |
|---|---|---|---|---|
| 零樣本(Zero-shot) | 簡單任務 | 快速、直接 | 複雜任務效果差 | ⭐⭐⭐ |
| 少樣本(Few-shot) | 格式化輸出 | 結果可控 | 需要準備示例 | ⭐⭐⭐⭐ |
| 思維鏈(CoT) | 複雜推理 | 推理過程透明 | Token消耗大 | ⭐⭐⭐⭐⭐ |
| ReAct | 工具調用 | 可執行動作 | 需要工具支持 | ⭐⭐⭐⭐ |
| 思維樹(ToT) | 多路徑決策 | 探索更全面 | 計算成本高 | ⭐⭐⭐ |
提示策略實戰演示
以下截圖展示了在OpenWebUI中使用不同提示策略的實際效果:
OpenWebUI界面
OpenWebUI聊天界面,支持與各種LLM模型對話
1. 零樣本提示(Zero-shot)
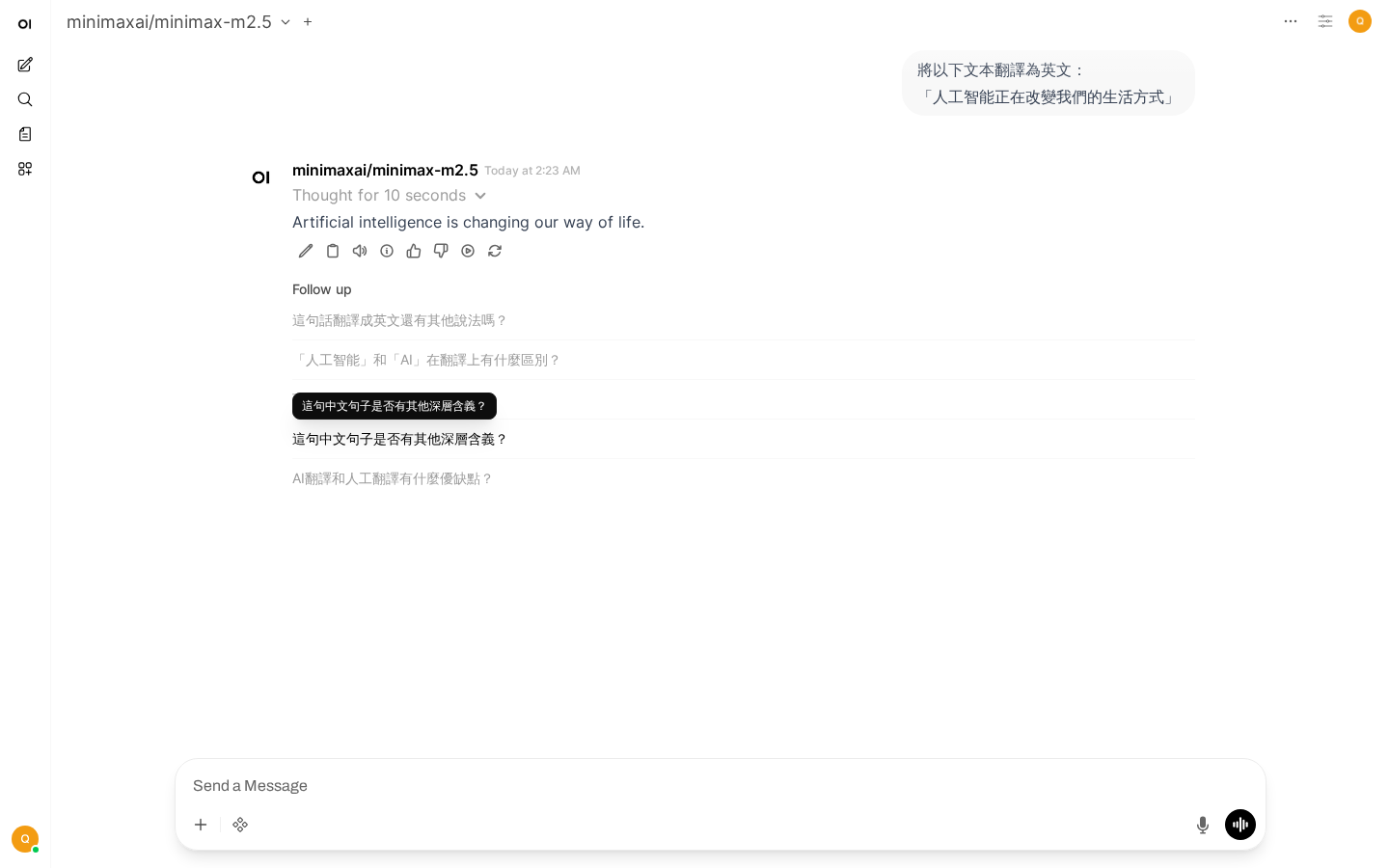
直接提問,AI立即給出翻譯結果
2. 少樣本提示(Few-shot)
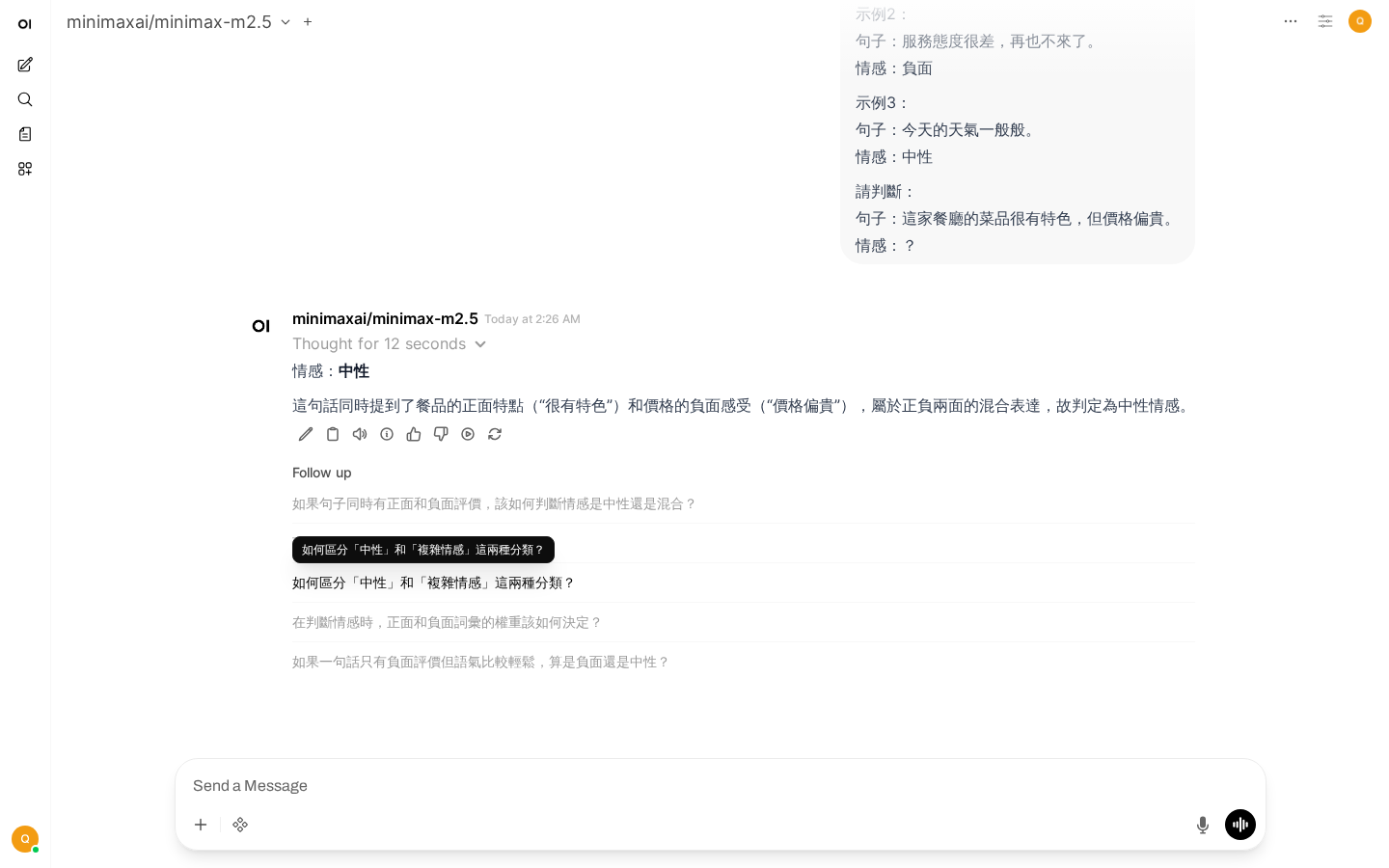
通過示例引導AI學習情感分類模式
3. 思維鏈(Chain of Thought)
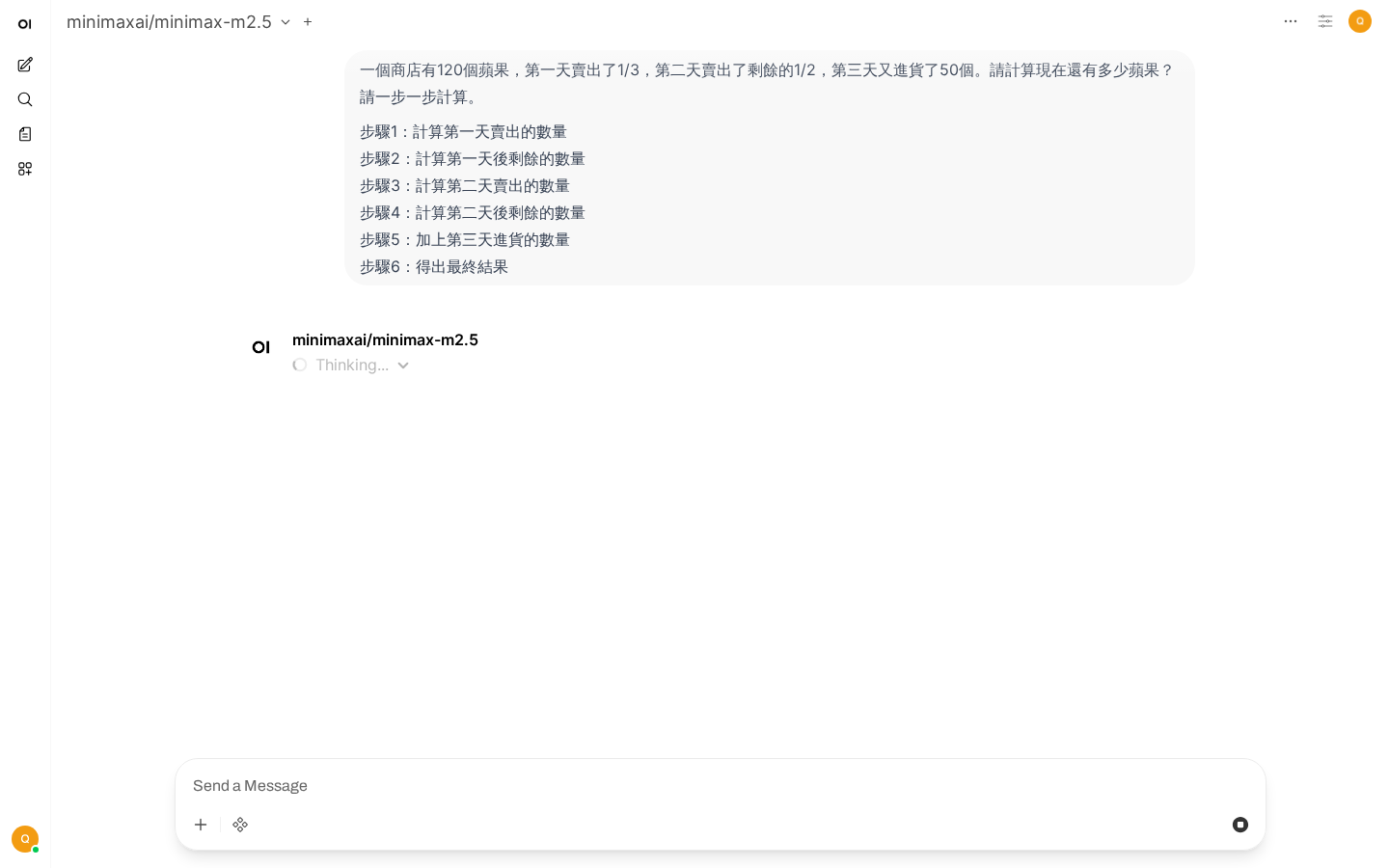
逐步推理過程,AI按步驟計算結果
4. 角色扮演
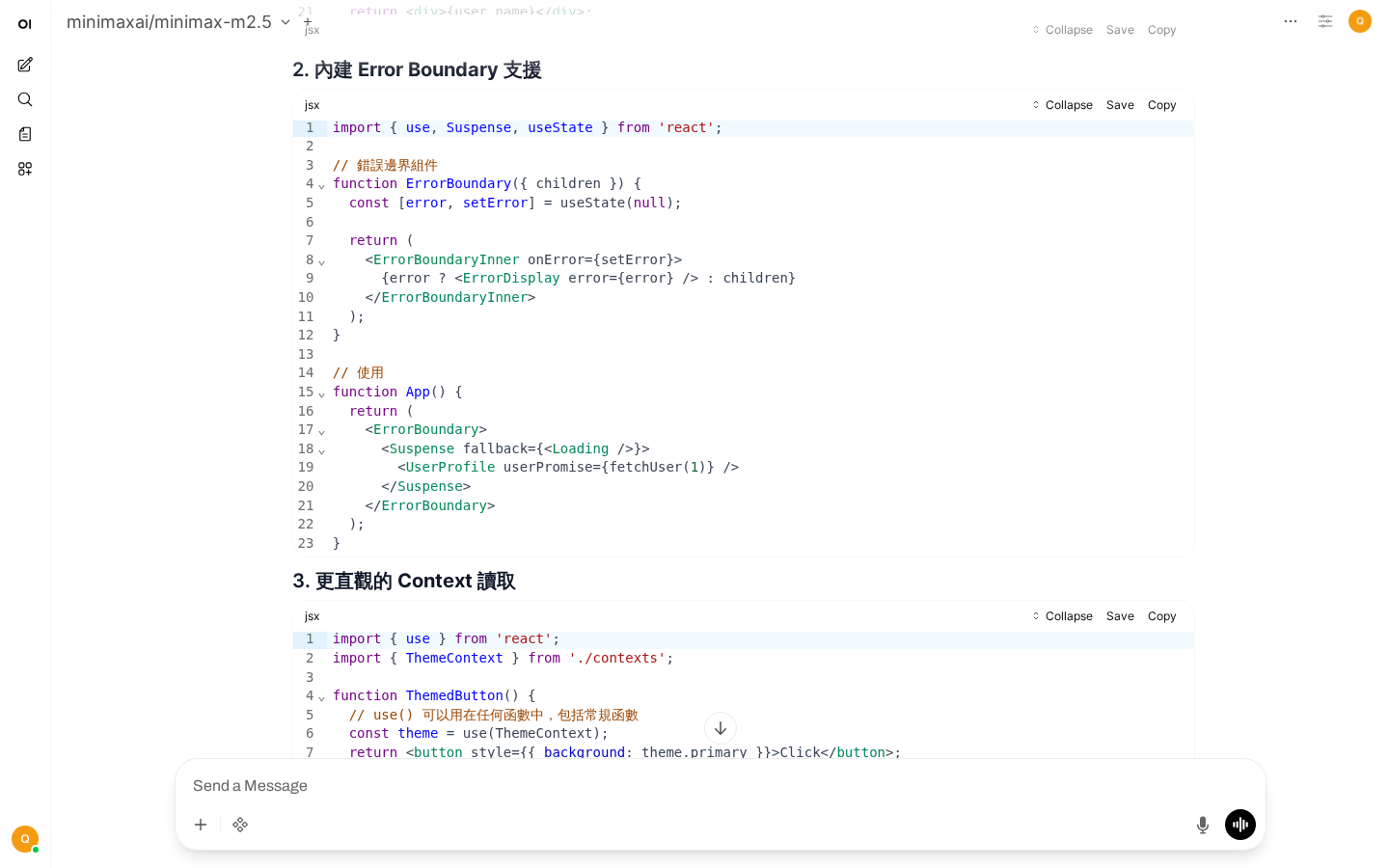
AI以React專家身份給出專業回答
5. 結構化輸出
要求JSON格式返回,結果可直接解析使用
6. ReAct模式

推理+行動模式,AI系統性分析技術選型
1. 零樣本提示(Zero-shot)
直接提問,不提供示例:
將以下文本翻譯為英文:
「人工智能正在改變我們的生活方式」適用場景:翻譯、摘要、簡單問答
2. 少樣本提示(Few-shot)
提供示例讓AI學習模式:
判斷以下句子的情感傾向:
示例1:
句子:這部電影太精彩了!
情感:正面
示例2:
句子:服務態度很差,再也不來了。
情感:負面
示例3:
句子:今天的天气一般般。
情感:中性
請判斷:
句子:這家餐廳的菜品很有特色,但價格偏貴。
情感:?適用場景:分類、格式化輸出、風格模仿
3. 思維鏈(Chain of Thought)
引導AI逐步推理:
一個商店有120個蘋果,第一天賣出了1/3,
第二天賣出了剩餘的1/2,第三天又進貨了50個。
請計算現在還有多少蘋果?請一步一步計算。
步驟1:計算第一天賣出的數量
步驟2:計算第一天後剩餘的數量
步驟3:計算第二天賣出的數量
步驟4:計算第二天後剩餘的數量
步驟5:加上第三天進貨的數量
步驟6:得出最終結果適用場景:數學推理、邏輯分析、複雜問題
4. ReAct(推理+行動)
結合推理和工具調用:
你是一個AI助手,可以使用以下工具:
- search(query): 搜索網絡信息
- calculate(expression): 計算數學表達式
- weather(location): 查詢天氣
問題:北京今天的天氣如何?適合戶外運動嗎?
思考過程:
1. 需要查詢北京今天的天氣
2. 調用 weather("北京")
3. 根據溫度、濕度、空氣質量判斷是否適合運動適用場景:問答系統、自動化任務、研究調研
5. 思維樹(Tree of Thoughts)
探索多條推理路徑:
問題:創業應該選擇哪個方向?
請從多個角度思考,每個角度提出2-3個選項,
然後評估每個選項的優缺點,最後綜合給出建議。
角度1:市場需求
角度2:技術門檻
角度3:資金要求
角度4:競爭格局
每個角度列出可能的選項,評估後選擇最優路徑。適用場景:決策分析、創意生成、策略規劃
三個實戰案例
graph TB
subgraph 實戰案例應用場景
A[案例1<br/>代碼生成] --> A1[Python函數開發]
A --> A2[配置文件解析]
A --> A3[錯誤處理實現]
B[案例2<br/>數據分析] --> B1[銷售數據分析]
B --> B2[趨勢預測]
B --> B3[報告生成]
C[案例3<br/>內容創作] --> C1[博客大綱]
C --> C2[技術文檔]
C --> C3[教程編寫]
end
style A fill:#e3f2fd
style B fill:#e8f5e9
style C fill:#fff3e0案例1:代碼生成助手
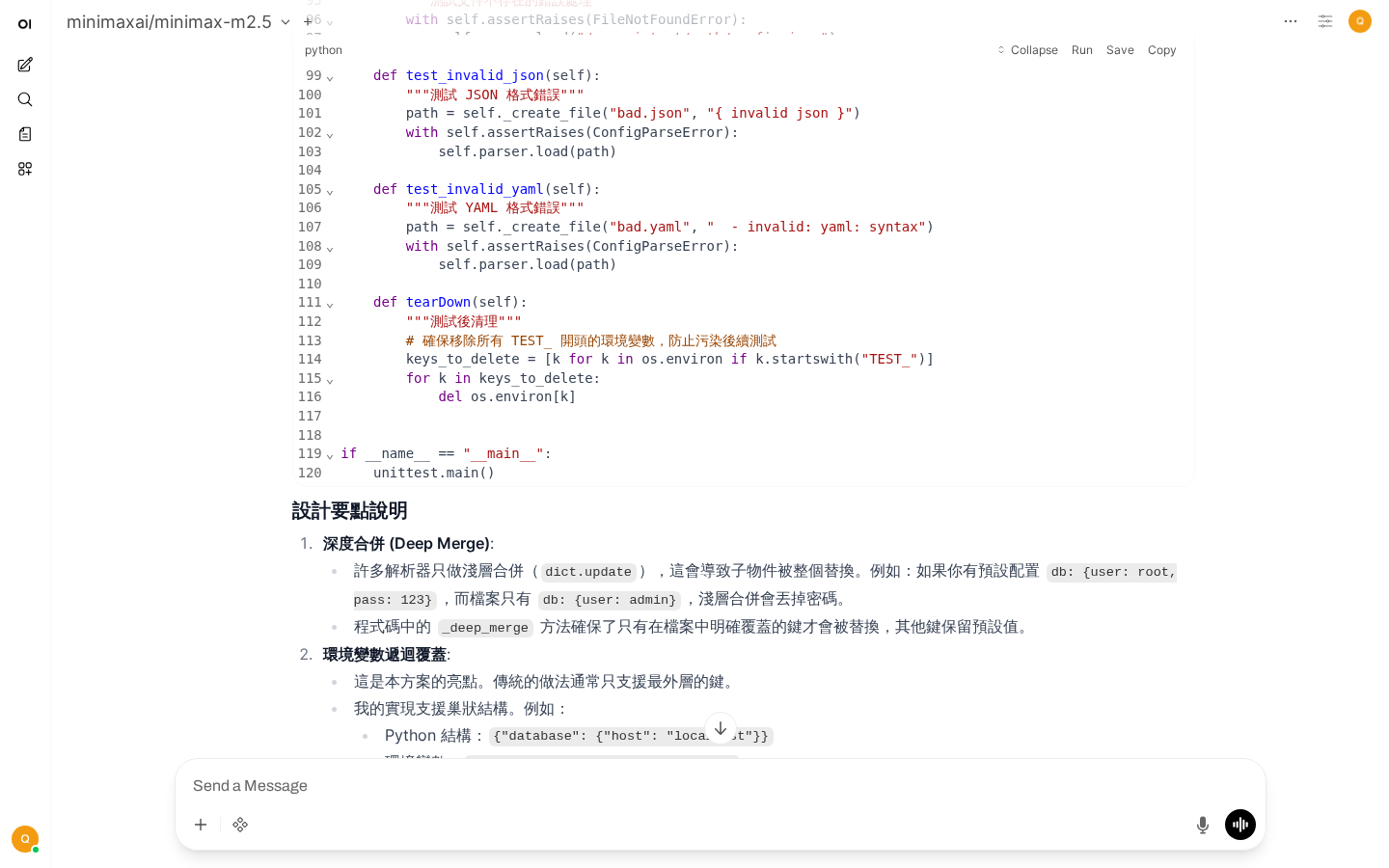
AI生成的Python配置解析器代碼
需求:讓AI生成一個Python函數,解析JSON配置文件
你是一位資深Python開發者,請編寫一個函數來解析JSON配置文件。
要求:
1. 函數名:parse_config
2. 參數:config_path(配置文件路徑)
3. 返回:配置字典
4. 錯誤處理:
- 文件不存在時返回默認配置
- JSON格式錯誤時拋出異常並提示具體位置
5. 支持環境變量覆蓋配置項
6. 添加完整的類型註解和文檔字符串
示例配置文件格式:
{
"database": {
"host": "localhost",
"port": 5432,
"name": "myapp"
},
"logging": {
"level": "INFO",
"file": "app.log"
}
}
請提供完整代碼,包括單元測試。AI輸出要點:
- 使用
json.load()和try-except - 使用
dataclasses定義配置類 - 使用
os.environ.get()覆蓋配置 - 使用
pytest編寫測試
案例2:數據分析報告生成

AI生成的銷售數據分析報告
需求:從銷售數據生成分析報告
你是一位數據分析師,請根據以下銷售數據生成分析報告。
數據:
| 月份 | 產品A | 產品B | 產品C | 總計 |
|------|-------|-------|-------|------|
| 1月 | 1200 | 800 | 500 | 2500 |
| 2月 | 1500 | 900 | 600 | 3000 |
| 3月 | 1100 | 1100 | 700 | 2900 |
報告要求:
1. 整體趨勢分析(哪個月最好?為什麼?)
2. 產品對比分析(哪個產品增長最快?)
3. 異常值檢測(有沒有異常數據?)
4. 下季度預測建議
5. 使用markdown表格展示數據
報告格式:
# 銷售數據分析報告
## 數據概覽
[表格和描述]
## 趨勢分析
[分析內容]
## 產品對比
[對比圖表描述]
## 異常檢測
[異常說明]
## 預測與建議
[建議內容]案例3:內容創作助手
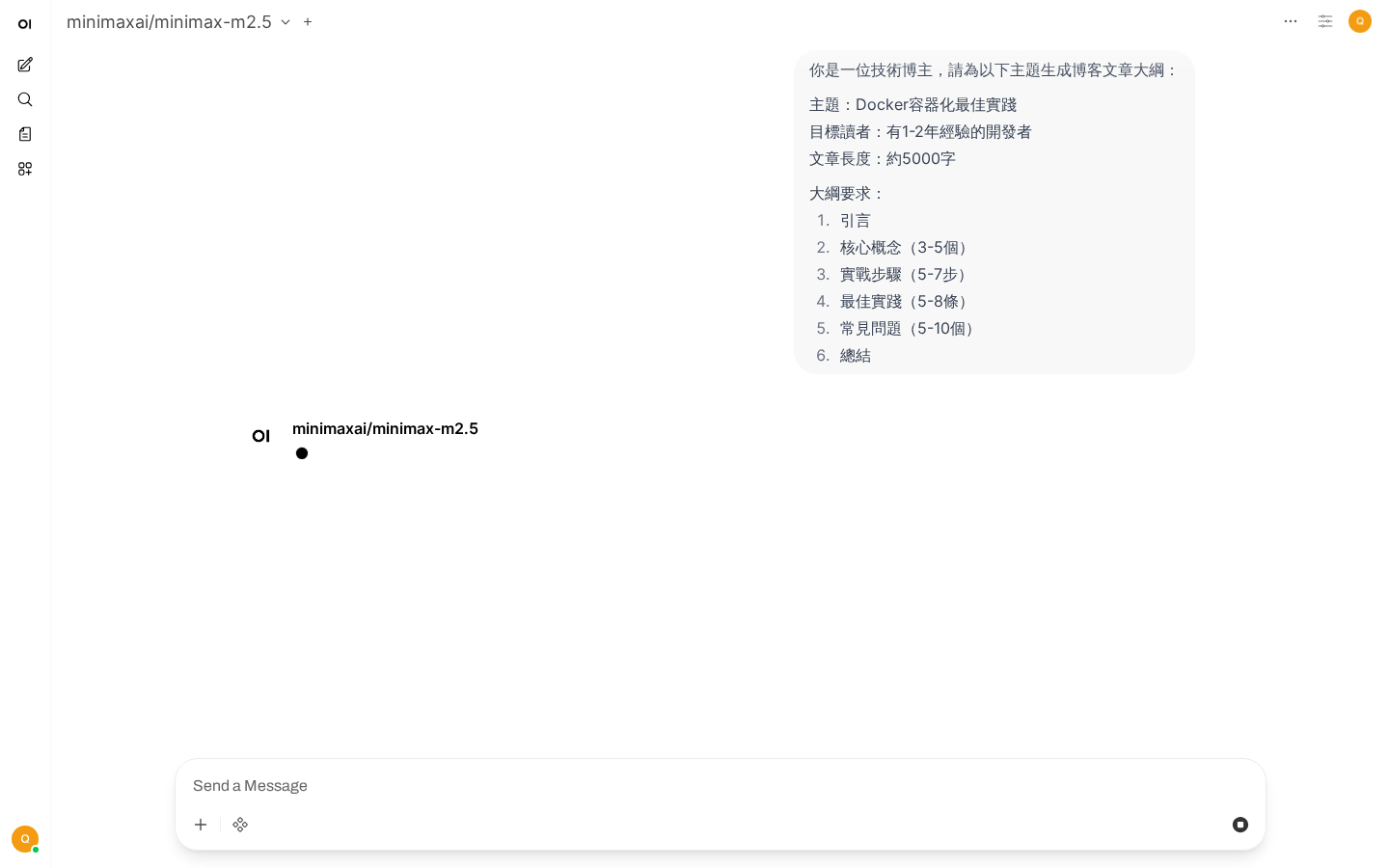
AI生成的Docker容器化博客大綱
需求:寫一篇技術博客文章大綱
你是一位技術博主,請為以下主題生成博客文章大綱:
主題:Docker容器化最佳實踐
目標讀者:有1-2年經驗的開發者
文章長度:約5000字
風格要求:
- 實用為主,理論為輔
- 包含代碼示例
- 包含常見問題解答
大綱要求:
1. 引言(為什麼要容器化)
2. 核心概念(3-5個)
3. 實戰步驟(5-7步)
4. 最佳實踐(5-8條)
5. 常見問題(5-10個)
6. 總結
請為每個部分提供:
- 預計字數
- 核心要點
- 代碼示例提示進階技巧
思維鏈進階:自我一致性(Self-Consistency)
讓AI從多個推理路徑中選擇最可靠的結果:
請用三種不同的方法解決這個問題,然後比較結果:
問題:一個投資組合的年化收益率是多少?
- 初始投資:100萬
- 第一年末:110萬
- 第二年末:125萬
- 第三年末:140萬
方法1:簡單平均法
方法2:幾何平均法
方法3:時間加權法
請分別計算,然後說明哪種方法更適合這個場景。ReAct進階:多工具協作
你是一個研究助手,需要完成以下任務:
任務:分析「人工智能在醫療領域的應用」
可用工具:
- search(query): 搜索學術論文
- summarize(text): 縮長文本
- translate(text, lang): 翻譯文本
- extract_keywords(text): 提取關鍵詞
執行計劃:
1. 搜索相關論文(至少5篇)
2. 提取每篇論文的關鍵詞
3. 總結每篇論文的核心貢獻
4. 綜合分析,生成研究報告
請逐步執行並記錄每一步的結果。提示模板複用
創建可複用的提示模板:
# prompt_templates.py
CODE_REVIEW_TEMPLATE = """
你是一位代碼審查專家,請審查以下代碼:
語言:{language}
文件:{filename}
代碼:
```{language}
{code}請從以下角度審查:
- 代碼風格(命名、格式)
- 潛在bug(空指針、邊界條件)
- 性能問題(時間/空間複雜度)
- 安全問題(注入、敏感數據)
- 可維護性(註釋、結構)
輸出格式:
問題列表
| 行號 | 類型 | 描述 | 建議 |
|---|
總體評分
X/10
改進建議
[具體建議] """
使用
prompt = CODE_REVIEW_TEMPLATE.format( language=“python”, filename=“utils.py”, code=code_content )
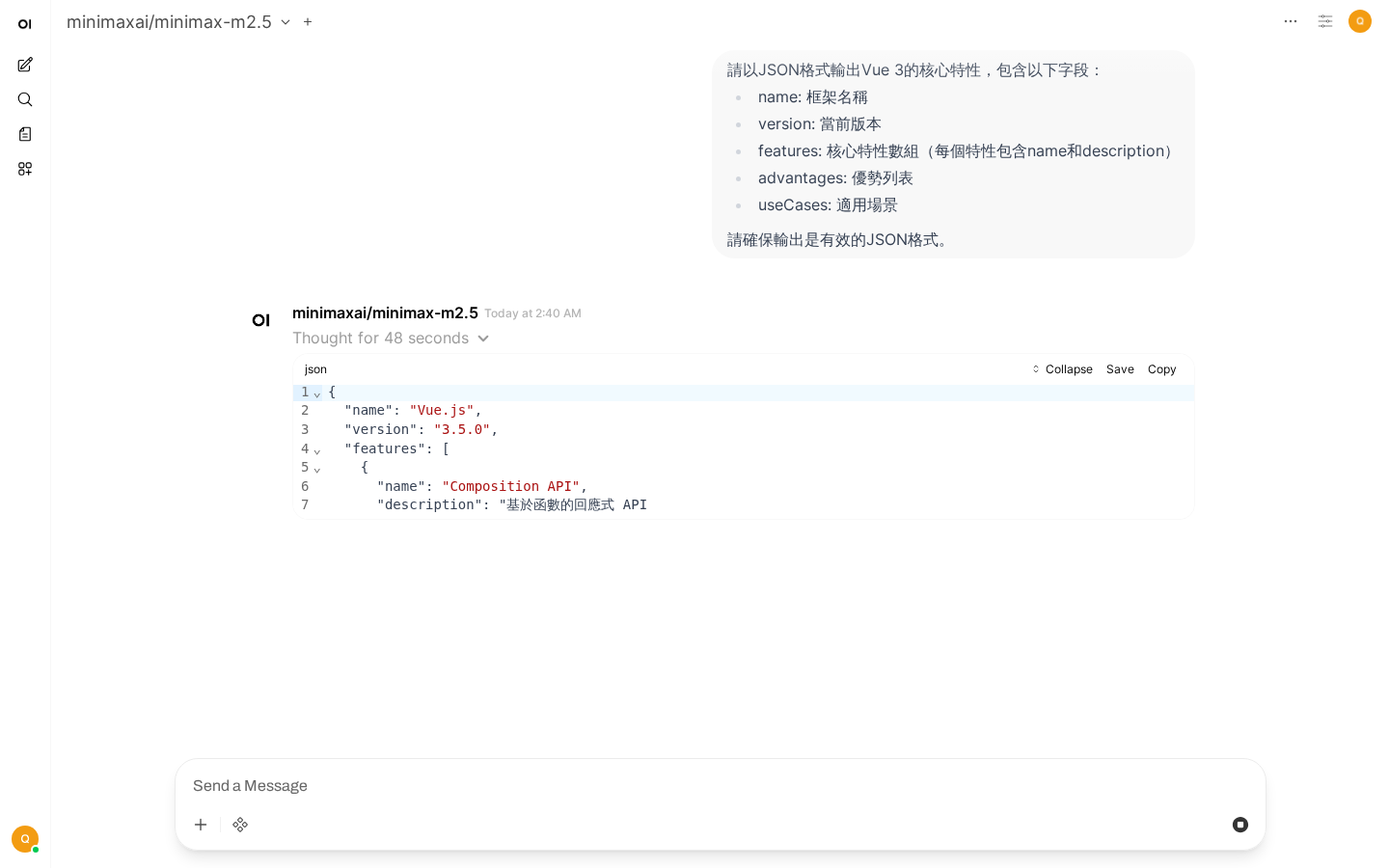
## 十個常見問題解答
### Q1: 為什麼AI的回答有時會「幻覺」?
**原因**:LLM基於概率生成文本,可能生成看似合理但實際不正確的內容。
**解決方案**:
- 要求AI標註信息來源
- 使用RAG(檢索增強生成)
- 對關鍵信息進行事實核查
- 添加約束:「如果你不確定,請直接說不知道」
### Q2: 如何讓AI輸出更穩定一致?
**解決方案**:
```text
請嚴格按照以下格式輸出,不要添加任何額外內容:
{
"summary": "一句話總結",
"key_points": ["要點1", "要點2", "要點3"],
"confidence": "高/中/低"
}Q3: 如何處理長文本輸入?
解決方案:
- 分段處理,逐步總結
- 使用滑動窗口技術
- 先提取關鍵信息,再進行分析
Q4: 如何讓AI記住之前的對話?
解決方案:
- 在提示中包含對話歷史
- 使用API的messages參數傳遞上下文
- 總結之前的對話要點作為新的提示
Q5: 不同LLM的提示策略有區別嗎?
對比:
| 模型 | 特點 | 提示建議 |
|---|---|---|
| GPT-4 | 推理能力強 | 可用複雜提示 |
| Claude | 長文本處理好 | 可輸入大量上下文 |
| Llama | 開源可定製 | 需要更明確的指令 |
| Gemini | 多模態 | 可結合圖像輸入 |
Q6: 如何評估提示的效果?
評估方法:
- A/B測試不同提示
- 使用基準測試集
- 人工評估質量
- 監控輸出一致性
Q7: 如何處理敏感話題?
解決方案:
請以客觀、中立的方式回答,如果問題涉及敏感內容,
請提供多方觀點,並標註信息來源。Q8: 如何讓AI生成代碼更規範?
解決方案:
請生成符合以下規範的代碼:
- 使用PEP8風格(Python)
- 添加類型註解
- 添加docstring
- 包含錯誤處理
- 編寫單元測試Q9: 如何減少Token消耗?
解決方案:
- 精簡提示,去除冗餘
- 使用縮寫和代號
- 分批處理長任務
- 緩存常用結果
Q10: 如何持續改進提示?
迭代流程:
- 記錄當前提示和結果
- 分析不足之處
- 修改提示
- 對比結果
- 保留最佳版本
最佳實踐清單
提示模板庫
代碼生成模板
語言:{language}
任務:{task}
要求:
- {requirement1}
- {requirement2}
- {requirement3}
請提供:
1. 完整代碼
2. 使用示例
3. 注意事項文檔撰寫模板
主題:{topic}
受眾:{audience}
長度:{length}
大綱:
1. 背景
2. 核心內容
3. 實例
4. 總結
風格:{style}數據分析模板
數據:{data_description}
目標:{analysis_goal}
請提供:
1. 數據概覽
2. 趨勢分析
3. 異常檢測
4. 建議方案
格式:使用表格和圖表描述提示工程最佳習慣
- 迭代優化:根據結果不斷調整提示
- 保存有效提示:建立個人的提示模板庫
- 理解模型特性:不同模型可能需要不同的提示策略
- 注意隱私:不要在提示中包含敏感信息
- 版本管理:對重要提示進行版本控制
- 文檔化:記錄提示的設計思路和效果
總結
提示工程是一項需要不斷練習的技能。通過本指南,你已經掌握了:
- ✅ 提示工程的基本概念和原則
- ✅ 5種核心提示策略的對比與選擇
- ✅ 3個完整的實戰案例
- ✅ 進階技巧:思維鏈、ReAct、思維樹
- ✅ 10個常見問題與解決方案
- ✅ 可複用的提示模板庫
記住:好的提示 = 清晰的目標 + 足夠的上下文 + 適當的結構。持續練習,你會發現與AI的溝通越來越順暢。


💬 評論區